Semantische Textanalyse für deutsche Texte
Unbestritten ist, dass die Menge der produzierten Daten exponentiell wächst. Doch nicht nur das Datenvolumen steigt, auch die Zusammensetzung der Daten ändert sich. Der größte Teil der Daten liegt in unstrukturierter Form vor und zum beträchtlichen Teil handelt es sich hierbei um Texte, zum Beispiel in Form von Artikeln, Dokumenten, E-Mails, Websites, Befragungen, Studien oder Beiträgen. Diese auszuwerten erfordert viel Zeit. Um diesen Daten Herr zu werden, werden spezialisierte Werkzeuge benötigt. Dies ist die Domäne der semantischen Textanalyse. Peter Adolphs, ehemaliger Head of Research der Neofonie, gibt einen Überblick über Anwendungsfelder, Tools und Herausforderungen der automatisierten Textanalyse, um die Bedeutung der Texte auswerten und charakterisieren zu können.
Anwendungsfelder und Nutzen der Textanalyse
Ein frühes Beispiel für die kommerzielle Nutzung von Textanalyse-Verfahren ist Google AdSense. Dieser Dienst platziert textuelle Werbeanzeigen auf Webseiten anhand der thematischen Nähe von Anzeige und Websiteinhalt. Eine wirkliche mediale Aufmerksamkeit erreichte semantische Textanalyse aber erst in diesem Jahrzehnt, und zwar auf dem Gebiet der automatischen Fragebeantwortung. Anfang 2011 trat IBM mit seinem Watson System in der Fernseh-Show Jeopardy gegen zwei Gewinner der Show an und schlug diese um Längen. Im Oktober desselben Jahres stellte Apple sein Siri System als das Haupt-Feature des neuen iPhones vor. Beide Ereignisse sind wichtige Wegmarken für eine Öffnung von semantischen Technologien für die breite Masse.
Semantische Technologien erlauben es, Schlüsselwörter für Texte automatisch zu ermitteln, Personennamen zu erkennen und auch große Mengen von Dokumenten automatisch zu klassifizieren bzw. bestimmten Themenbereichen zuzuordnen. Damit sind diese Technologien für alle Unternehmen und Branchen relevant, die Texte produzieren (etwa Redaktionen und Verlage), Textarchive aufbereiten (Bibliotheken) oder in denen laufend große Textmengen anfallen (zum Beispiel Support-Center). So werden Redakteure durch die automatische Identifikation von Schlüsselwörtern bei der Verschlagwortung ihrer Artikel unterstützt. Ebenso lassen sich mit dieser Technologie Themenseiten (Topic Pages) vollkommen automatisiert erstellen, was nicht zuletzt für die Positionierung der eigenen Seiten bei den großen Suchmaschinen relevant ist.
Getrieben wird der Bereich auch durch die Auswertung von Textbeiträgen in sozialen Medien (soziale Netzwerke, Blogs und Foren), um für den Anwendungsfall Social Media Monitoring Stimmungen und Diskussionen erfassen zu können (siehe Forschungsprojekt News-Stream 3.0). Unternehmen sind daran interessiert, wie die eigene Marke in den sozialen Medien wahrgenommen und diskutiert wird. Auch die Konkurrenz lässt sich mit semantischer Textanalyse beobachten und mit der eigenen Marke, dem eigenen Produkt vergleichen.
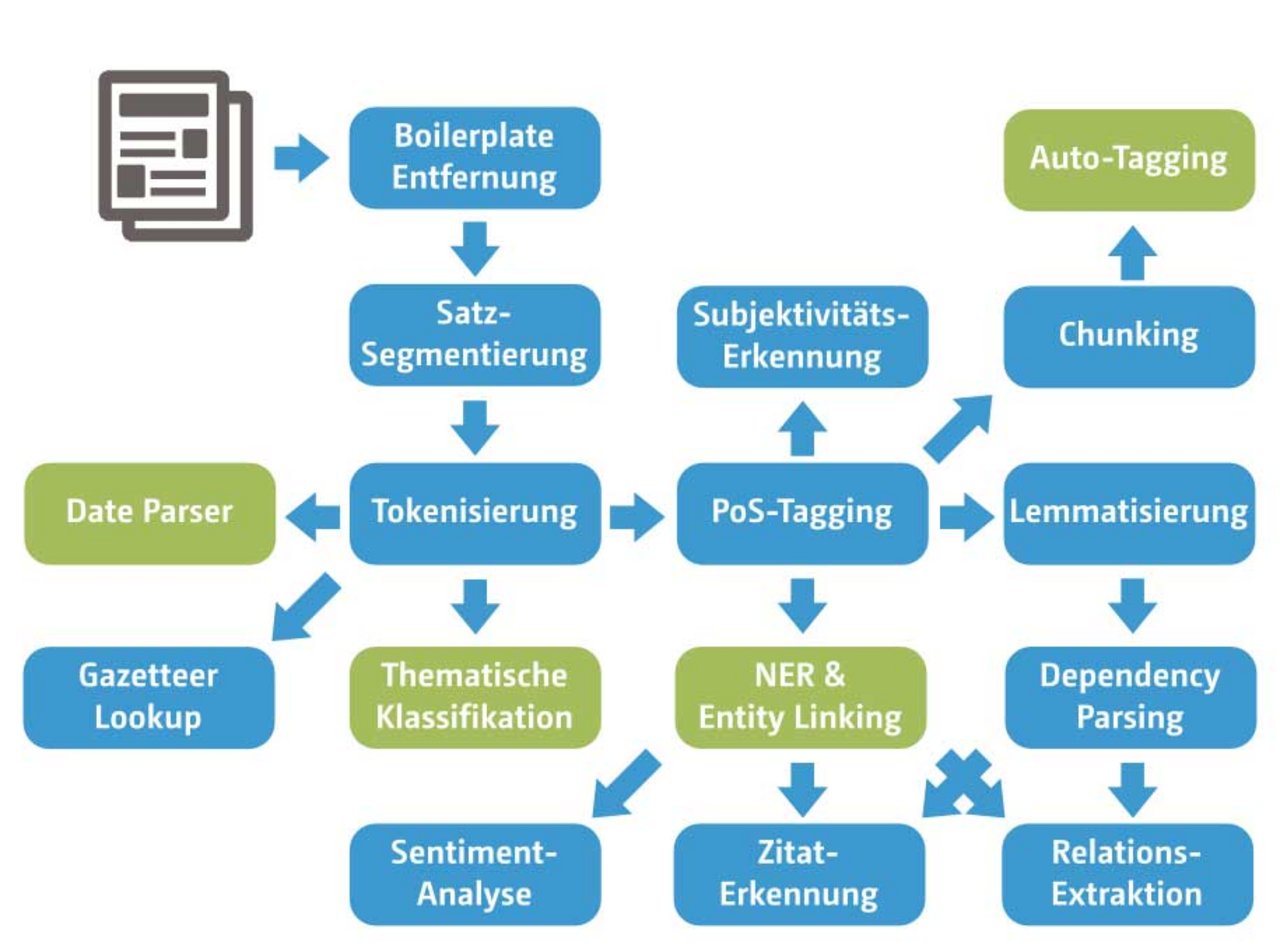
Gemüse oder Altbundeskanzler „Kohl“?
Für die Analyse von Personen, Organisationen oder Orten in einem Text, wäre es naheliegend den Text mithilfe von Lexika zu durchsuchen. Allerdings ist dies aus mehreren Gründen nicht ganz so trivial, wie es auf den ersten Blick scheint. Zum einen kann ein Lexikon aller bekannten Personen, Organisationen und Orte sehr groß werden. So listet die Wissensbasis DBPedia etwa 1,4 Millionen Personen für die englische Sprache und immerhin noch 180 Tausend Personen für die deutsche Sprache. Hier müssen entsprechende Technologien (zum Beispiel endliche Automaten) für einen effizienten Lookup verwendet werden. Noch schlimmer ist allerdings das Problem der Mehrdeutigkeit: längst nicht jeder Treffer aus einem Personenlexikon bezeichnet auch eine Person. Das Wort “Kohl” in einem Text kann das Gemüse oder den Altbundeskanzler zum Gegenstand haben. Zudem sind Lexika immer(!) unvollständig.
Statt lexikonbasierter Named Entity Recognition (NER) werden daher in der Regel offene NER Systeme eingesetzt, die maschinell gelernt sind und versuchen, Namenserwähnungen anhand des linguistischen Kontexts als solches zu erkennen. Dennoch sind Lexika nicht bedeutungslos. Wissensbasen wie DBPedia oder Freebase sind letztlich digitale Modelle der Welt und bieten eindeutige Bezeichner für Entitäten in der Welt. Wurde die namentliche Erwähnung einer Entität erst einmal identifiziert, ist der nächste Schritt die Referenzauflösung in Bezug auf so eine Wissensbasis. Auch hier stellt sich – wie so oft bei der maschinellen Sprachverarbeitung – das Problem der Mehrdeutigkeit. Handelt es sich bei “Peter Müller” um den deutschen Politiker oder den Skifahrer? Oder wird hier ein weiterer Namensvetter erwähnt, einer, der noch nicht die Popularität erreicht hat, um in einer der Wissensbasen aufgeführt zu werden?
Tools und Werkzeuge
In den letzten Jahren sind etliche Textanalyse-Komponenten als Open Source verfügbar gemacht worden. Projekte wie Apache OpenNLP oder die mate-tools bieten generelle Werkzeuge und die zugehörigen sprachspezifischen Modelle für grundlegende linguistische Textanalysen (Segmentierung, Wortart-Zuweisung, Bestimmung von Wortgrundformen, Syntax-Analyse). Mit GATE und Apache UIMA existieren auch Frameworks für den Aufbau ganzer NLP-Pipelines. ClearTK und DKPro stellen Repositories für UIMA bereit, die konkrete NLP-Werkzeuge und Modelle bündeln und integrieren. Allerdings ist die Lernkurve bei all diesen Tools hoch und es sind noch einige weitere Lücken zu schließen, bevor man zu einer semantischen Repräsentation der Texte gelangt.
Wesentlich einfacher ist die Nutzung von Textanalyse-Diensten aus der Cloud. Führende Anbieter sind hier AlchemyAPI und Semantria aus den USA. Neofonie aus Berlin stellt mit TXTWerk API eine Auswahl wichtiger Textanalyse Dienste speziell für deutschsprachige Texte als JSON REST Service zur Verfügung. Beim „Entity Recognition and Disambiguation Challenge 2014“ von Microsoft und Google belegte Neofonie weltweit den sechsten Platz, in puncto Geschwindigkeit sogar den zweiten.
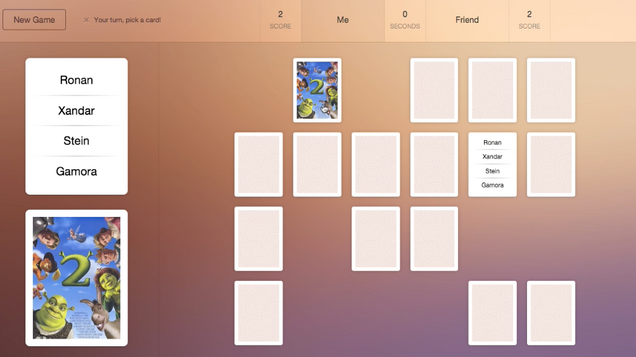
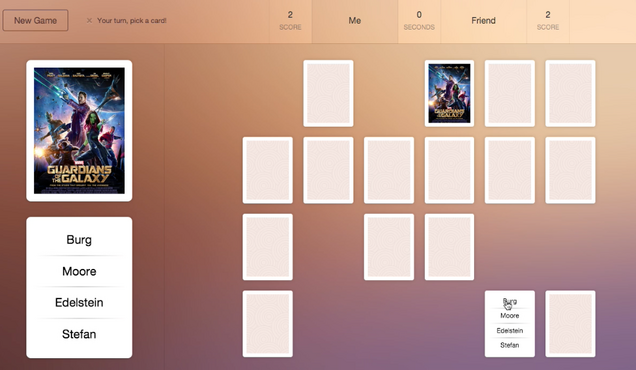
Wie mit der TXT Werk API ein Movie Game entstand
Ende Oktober fand in der Location AHOY! Berlin ein Event für Entwickler – das TMU Hack – statt. Innerhalb von 32 Stunden konnten die Teilnehmer ihre Ideen umsetzen. Auf Basis des Textanalyse Tools TXT Werk API von Neofonie entwickelte ein Team aus sechs Personen ein Kartenlegespiel für Filmkenner: Movie Match Mastery. Jan Mechtel war im Entwicklerteam, Neofonie hat ihn interviewt.
Was hat dich an der Teilnahme des TMU Hackathon gereizt?
Hackathons sind für mich immer eine tolle Erfahrung – die perfekte Umgebung neue Technologien und Leute kennenzulernen und sich gleichzeitig der Herausforderung zu stellen, etwas „rundes“ in kurzer Zeit auf die Beine zu stellen.
Wie kam das Team zustande?
Unser magisches Team kam wie von selbst zustande und bestand aus Alex Dubovskoy, Matthias Loker (Frontend) und Stefan Hintz, (Design & Frontend) sowie Jeremy Tammik, Daniel Karch und mir (backend). Stefan Hintz und ich haben uns zusammen angemeldet. Wir haben schon vorher zusammen gearbeitet (bei www.veodin.com) und gingen deshalb gemeinsam ins Brainstorming.
Warum habt ihr euch für die TXT Werk API entschieden?
Wir haben erst einmal geschaut, welche Tools zur Verfügung gestellt wurden und überlegt, was wir bauen wollen. Natural Language Processing und semantische Textanalysen sind ein spannendes Feld, in dem sich in den letzten Jahren viel getan hat. Als wir die TXT Werk API gesehen haben, wussten wir, dass wir damit etwas Cooles bauen können. Stefan ist ein guter Designer. Wir wollen, dass unsere Hacks immer toll aussehen sollen. So entstand die Idee für Movie Match Mastery.
Wie seid ihr vorgegangen?
Heiko Ehrig von Neofonie konnte uns am Anfang schnell mit der API vertraut machen und eine Machbarkeitsschätzung abgeben. Anfangs gab es noch Pläne mit den Entitäten (Personen, Orte etc.) von TXT Werk zu arbeiten, aber das haben wir zeitlich nicht geschafft. Zunächst mussten wir Filme und deren Textzusammenfassung besorgen, wobei wir auf imdb.com und wikipedia.de fündig wurden. Die Zusammenfassungen haben wir anschließend durch die TXT Werk API geschleust und damit die Schlüsselwörter extrahiert. Gleichzeitig haben wir eine neue Domain registriert und eine Frontend App mit AngularJS und yeoman aufgesetzt. Im Backend haben wir Firebase eingesetzt.
Wie funktioniert Movie Match Mistery?
Movie Match Mastery ist ein Kartenlegespiel, bei dem Paare gefunden werden müssen. Statt zwei gleicher Karten sollen Filmplakat und Handlungen zusammen gebracht werden. Während auf einer Karte das Cover des Films gezeigt wird, werden auf der anderen Karte die vier Haupt-Keywords der Textzusammenfassung des Films gezeigt. Ermittelt wurden die Schlüsselwörter über die Autotagger-Funktionalität der TXT Werk API. Erschwert wird das Spiel durch eine Zeitbegrenzung. Erforderlich sind mindestens zwei Spieler, die an unterschiedlichen Orten webbasiert gegeneinander spielen können.
Textanalyse-Tool – TXT Werk API
Mit TXT Werk können beliebige Texte nach semantischen Gesichtspunkten analysiert und automatisch mit Schlagworten und Metadaten angereichert werden. Die Texte werden thematisch klassifiziert, Schlagworte werden automatisch extrahiert, Daten und Zeiträume sowie Namenserwähnungen von Orten, Personen und Organisationen (Named Entities) werden erkannt und mit URIs aus dem Freebase Knowledge Graph verlinkt. Entwickler sind mit Hilfe der sehr schlanken JSON Rest API in der Lage, in ihren Anwendungen unstrukturierte Texte anzureichern und in die Linked Open Data Welt zu vernetzen.
Entwickler sind eingeladen, auf Basis der API eigene Ideen umzusetzen und können dazu bis zu einem bestimmten Datenvolumen die API kostenfrei nutzen.
Interview-Partner: Jan Mechtel
Jan Mechtel ist Geschäftsführer und Gesellschafter bei Veodin Software, und entwickelt seit 4 Jahren Spezialsoftware für große Unternehmensberatungen, Banken und Wirtschaftsprüfer. Hauptprodukte sind KeyRocket, ein Trainer für Tastaturkürzel, und SlideProof, ein Add-in für PowerPoint zur Endformatierung. Er ist ein Hybrid aus zahlengetriebenem Berater und Softwareentwickler (Autodidakt).
Erfahren Sie mehr über Ursprünge und Entwicklungen, wie konkrete Analyseabfragen aussehen und welche Bedeutung NLP spielt.
Lesen Sie den vollständigen Artikel in unserem Whitepaper: „Textanalyse aus der Wolke“
Veröffentlichung am 10.06.2015, aktualisiert am 18.10.2020

Das könnte sie auch interessieren